Filter Assist: AI-Generated Filters in Todoist
How we leveraged AI to assist users when using our filter feature.
When the AI hype took the world by storm many companies started adding AI-infused capabilities to their product for the sake of it. VC money poured into every incumbent mentioning AI in their pitch deck, chat interfaces were everywhere. At Doist we’re taking a different approach to building high-quality products. Read on to learn how AI allowed us to solve a longstanding, real-world user problem in a much simpler yet incredibly powerful way.
The Opportunity
Todoist’s filters allow our users to find information quickly and efficiently, it’s ideal for those with large projects filled with tons of tasks. A filter consists of keywords and symbols, for example, today | overdue, and will return a list of tasks matching the criteria. However, the syntax is not always easy to grasp. As our CEO, Amir, once said :
[…] we have an incredibly powerful filtering engine, but it takes a Ph.D. in algebra to use it.
— Amir, CEO of Doist
The proof was in the fact that only a small percentage of users were adding filters.
The Solution
We were aware of the recent development of LLMs and their capabilities, and wanted to do some exploratory work on this whilst still addressing a solution to the real existing problem with filters. Thus, Todoist’s filters were the feature we landed on, based on low interaction rates and the assumption that the syntax surrounding forming filter queries is complex for new users.
We learned quickly that given a set of training data, AI would more often than not correctly return the intended results. However, given the nature of these queries (keywords alongside symbols, Todoist specific syntax for referencing projects, labels etc), we had some exploring to do to assert feasibility.
Here’s an example of a filter query to put into perspective the context required to form one:
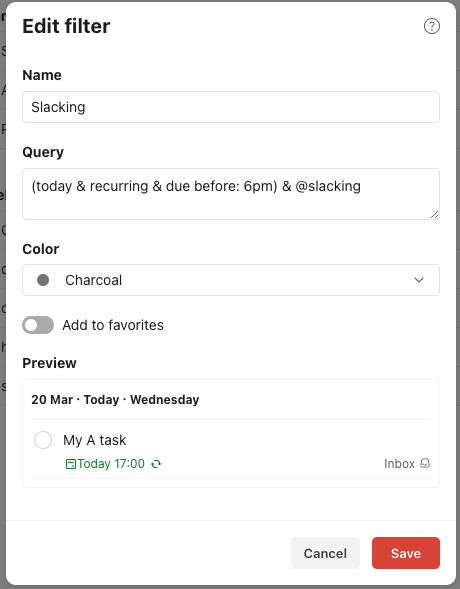
The above filter is just an example of what we can do with this powerful engine. However, this syntax would not necessarily be easily achievable by new users off the bat.
We initially explored approaching this from a non-AI perspective, by using different buttons and chips to include/exclude project names, labels, priority etc. We found that this was not easily solvable, however, and so shelved the idea. It would have introduced a ton of complexity in our UI and still left unanswered questions around whether this would help create filters.
How could we assist these users in leveraging filters more effectively?
- Our solution: Use AI to easily create powerful Todoist filters ✨
- How: Allow users to enter a natural language request (i.e. show me all of my overdue tasks), and return a generated filter.
Technical aspects
Backend
API
We created a separate backend service for this work, which worked nicely as it decoupled us from other production code, allowing faster experimentation. We had to choose between two options: a Python based or a JS/TS based implementation.
- Python
- Would allow for an easier transfer of ownership and support to the backend team given their existing knowledge in the language
- Most machine learning libraries are written in Python, so we’d be at the forefront of all updates
- JS/TS
- All widely adopted tools have wrappers in JavaScript (i.e. langchain or OpenAI)
- Would mean frontend devs can contribute easily
Given a Python backend would satisfy our requirements, we opted for this. The result: a lightweight backend API built on top of FastAPI and served with Uvicorn .
Endpoints
Our main endpoint was /generate_filter. This was the first endpoint called in our Filter Assist flow, and was responsible for sending the user’s input to the backend and returning the generated model’s response as a JSON object.
/generate_filter
Params
{
"description": "All tasks due today",
"language": "en",
}
Response
{
"response_id": "52ab99b3dace4b939fc167f18c89ba4b",
"query": "today",
"name": "Today's due tasks"
}
We also added an endpoint to allow users to rate the response (either useful or not useful). The rating_type refers to whether the user explicitly interacted with our rating component (EXPLICIT) or asked to restart the process (IMPLICIT). In the latter’s case, we assumed a non-useful response.
/submit_filter_feedback
Params
{
"is_useful": true
"rating_type": "EXPLICIT"
"response_id": "52ab99b3dace4b939fc167f18c89ba4b"
}
Response
{
"response_id": "52ab99b3dace4b939fc167f18c89ba4b",
"query": "today",
"name": "Today's due tasks"
}
Database
LLMs are at times unpredictable, and being able to investigate the quality of generated filters in regards to accuracy (high fidelity to what was asked in the input), as well as performance, was important and made us store data. Storing this data also meant we had an opportunity to further fine-tune. Since we were working with a simple model, we opted for DynamoDB. Our database went onto storing:
- User input
- The model’s output
- Feedback sent on the output via the UI (more on this below)
- Meta data such as timestamps and response IDs
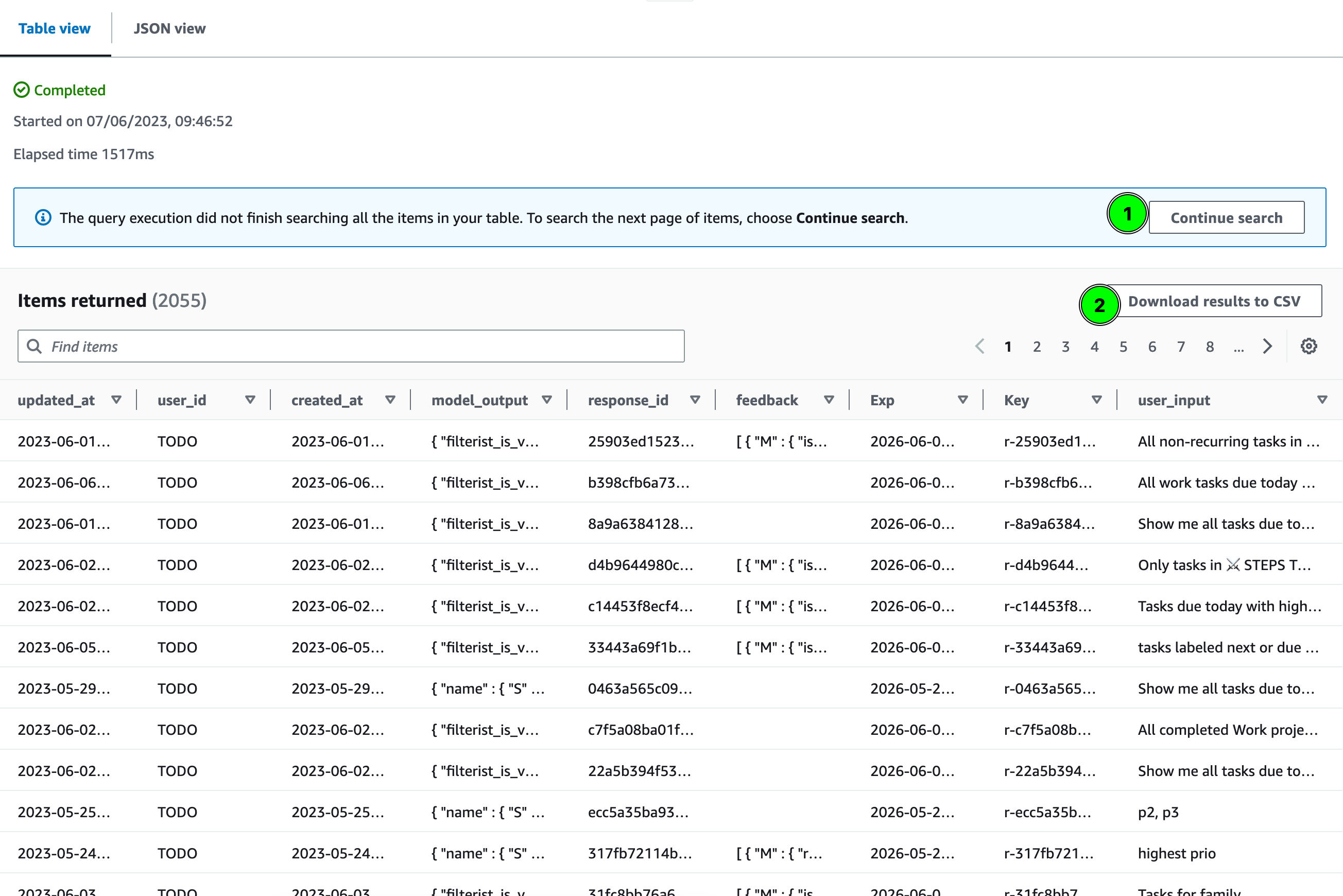
Database containing prompts, generated results and feedback.
Models
Our first task was to evaluate different AI models available to us. With several developers working on the initiative, we decided to split up and each explore options and their results within the context of our filters. We initially discussed building our own custom model and hosting it locally. As discussions matured, this approach turned out to be very expensive both from a time and infrastructure viewpoint. We wanted to ship something impactful to users fast. We also felt it would be a better approach to explore existing, well-tested implementations under a robust and reliable infrastructure first to get a sense of what exactly we needed from an AI model. We envisaged a custom model would come with a lot of overhead we may not have necessarily needed for our use case.
OpenAI, closed-source or third party models
Huggingface is a popular AI model hosting platform for the machine learning community, giving individuals the opportunity to consume and contribute to open-source models. The platform contains hundreds of models, each one fine-tuned depending on the use case (text to speech, text generation, image to 3D etc).
A few of us started running some queries against these models, namely Dolly . Some findings:
- Answers were returned between 11-150 seconds
- Complicated questions resulted in a an out of memory error
- Loading time was very slow (some 15 minutes)
Next up, we tried out GTP-3.5-turbo against GPT-4. Given 27 prompts on each, here’s what we found:
- GPT-3.5-turbo = 19/27 ~ 70%
- GPT-4 = 26/27 ~ 96%
These results were obtained by tweaking our training & rules sheet. The first run using our first draft of training data & rules resulted in a much lower score. But these results proved to be extremely useful in benchmarking both of these models.
Winning model: OpenAI’s GPT4 model.
Via our new backend, we queried OpenAI’s chat completions endpoint and specified our chosen model, along with other options such as max tokens and temperature (governing randomness and creativity). Our use case required as stable results as possible, so went for a low temperature (0.0).
Training & testing data
We carried out a technique called few-shot prompting, which involves augmenting our prompt with examples and expectations. We compiled a large sheet with different natural language prompts (i.e. show me all tasks due today with a priority of 1) and their expected outputs in query syntax.
We then compiled a separate set of data; testing data, to input into the model after the few-shot process to judge its accuracy.
Finally, we decided to increase the user’s experience by also training the model to output not just a filter query, but also a suggested title. A few examples showing case the final format of our training data sheets:
| prompt | completion | title |
|---|---|---|
| Tasks that are overdue or due today that are in the “Work” project | (today | overdue) & #Work | Today & overdue work tasks |
| Tasks that are due in the next 7 days and are labelled @waiting | 7 days & @waiting | Waiting next 7 days |
Frontend
By this point we had all the necessary puzzle pieces and configurations in place to train and obtain results from the OpenAI model:
- A FastAPI backend
- Endpoints for clients to generate a filter
- A model
- Training & testing data
- A database to store results
We now needed to wire up our backend to Todoist’s UI to see this magic in practice!
Todoist already has a modal from which users can create filters using queries, we decided to extend this form to include two approaches to creating a filter:
- The existing way, by entering the query directly
- An AI assisted way, by querying our API with plain english
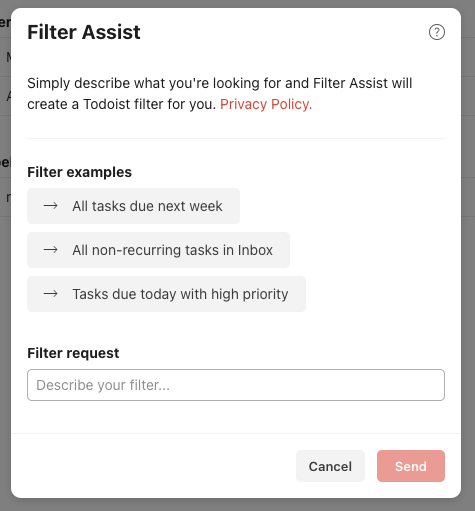
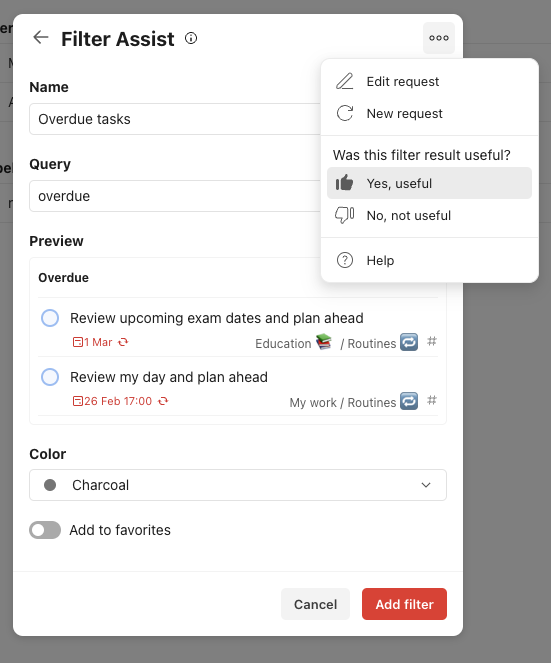
UI Refinements
As loading times differ between models, we wanted to ensure we had proper handling of such a situation if this ever was a problem. So we added a loading illustration as soon as the form was submitted to indicate a pause until our API returned the generated filter.
To further improve the experience, however, we also added a filter preview (this feature was added to the filter modal as a whole, whether used with AI or not, as we felt more experienced users might benefit from it). Sometimes the AI result was close enough, but still required some tweaks specific to the Todoist content, in such a case the preview was extremely useful.
Finally, to support the analysis of our model’s accuracy, we included a rating component allowing users to send feedback on the generated query. Additionally, we also allowed for them to restart the process (resulting in an implicit “no, not useful” rating), or edit the input slightly and re-try.
Challenges
Complying with the feature’s characteristics
No solution comes without its challenges, and this one was no different. There were several problems we had to solve to ensure that our model would not return any non-functional filters to users. Todoist leverages Filterist, our own inhouse filter library facilitating its creation and parsing according to the allowed syntax and queries. We had to ensure that anything not currently supported when used outside of AI was not returned by the filter.
An example of this would be returning an unsupported symbol. To mitigate this, we leveraged:
- A rules file. This file would contain a list of valid keywords and symbols. When training our model on testing data, we would ensure it also took into account these rules
- A sheet containing
NOT SUPPORTEDexamples as outputs - Our Filterist library validation on generated responses before returning the query back to the client
By design, we explicitly limit a filter’s max character count to 1024 in Todoist. Anything over this count would also be deemed an invalid generated filter when using AI. We were torn here between returning everything up to the max count, or invalidating it altogether. To reduce confusion, we opted for the latter. We specified a max_tokens property when querying OpenAI to safeguard against this, but we also added a rule in our rules file as an extra layer of protection: The filter query can't be longer than 1024 chars, if it is, output NOT SUPPORTED.
Rate limiting
To protect against high-volume usage, we have rate limits in place that consider a number of factors like the user and platform.
Final outcome
To recap, we wanted to use AI to easily create powerful Todoist filters. Our solution involved providing users with a UI to send plain English requests to a custom build API, from which we would invoke a GPT model to return a filter. We also added a filter preview and functionalities to retry and edit the request, and rate the experience.
Here’s a short demo of the final outcome 🎉:
The full flow show casing the creation of a filter using Filter Assist.
This feature is just one of many included in Todoist’s Pro subscription, sign up to make the most of Filter Assist and other powerful features today ✨.