Designing Explainable Machine Learning Products
Mistrust often comes from a lack of understanding
By Dominic Monn
At Doist, we are no strangers to Machine Learning. In fact, the first thoughts about ML at Doist happened 7 years ago! Over the years, Machine Learning was used both internally and in our products to make workflows smoother and ‘smarter’.
The sentiment towards ‘smart’ features has been mixed for as long as they’ve existed. The move away from configurable features and option-rich functions to ‘black boxes’ that are simply labelled as ‘smart’ can be unsettling. But – mistrust often comes from a lack of understanding and a fear of losing control.
Why we need to understand ML and ‘smartness’
‘Smartness’ and Machine Learning (ML) sit behind most products of big tech companies today, ranging from the smart assistant in your living room to tiny details, like which artwork Netflix shows for you .
We don’t often question why a certain mail lands in spam, why Amazon almost always knows what we need to purchase next or why typos are immediately pointed out when writing an email, we’re used to things working this way and being consistent.
But then when the ‘smart’ replies keep being a bit off, when our calendar reminds us of events we think are irrelevant, or we simply don’t understand how we suddenly get an ad for a product we just talked about the other day, the smartness in products becomes annoying or even a bit eerie.
So, what’s the difference? On one side, we have products that are incredibly accurate and explainable, ones where we think we understand how they’d work under the hood. In many cases, we can even check why an email is in the spam folder and we can take action to move the email somewhere else, even make sure that it doesn’t happen again. On the other hand, it’s sometimes hard to grasp why a certain ‘smart’ reply was picked for us, or scary to think about how Amazon knows about your upcoming need for a new mixer. We feel like we’re losing control.
The solution seems to be clear: As a product creator, we need to be able to create features that can be explained end-to-end and be understood by the user as well as the team creating it. While this is possible in traditional programming and with incredibly simple ML algorithms, that’s not always the case in all ML applications.
Can you explain the unexplainable?
When we talk about ML, the foundation of many ‘smart’ features, an algorithm or system may be so complex to the point where it’s not easily explained anymore.
In traditional programming, the software engineer defines the rules that a function needs to follow. When plugging in the data, it produces the answers. This works well when the rules of a function are clearly defined.
Rule: When I click button X, the form Y should open on the screen.
Since we defined the rules of the features, the behavior happens as we expected and defined, which means we can easily explain it as well.
Answer: Form Y opened because you clicked button X.
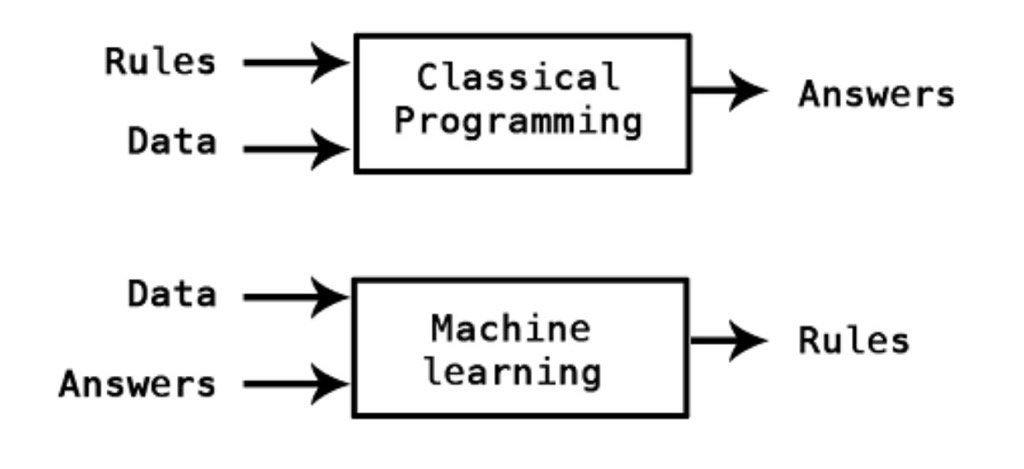
In ML however, engineers enter data and answers (called labelled data) and models learn abstract rules to go from data to answer. This means that we as engineers don’t know about the exact behaviour and set of rules a model has learned.
Data: Here’s data of a person’s past purchases on our site, here’s what they bought next
When we use this algorithm, we enter a person’s past purchases in the model and will get a prediction on the future purchase behavior, but not the rules that lead to it.
Answer: The algorithm predicts that the person is going to purchase product X next with high probability, but we’re not sure why.
Even though ML allows us compute deep relationships in the user’s purchasing behavior that would be difficult to define otherwise, the rules are not readable or very accessible to us.
Explaining ML in the wild
Does every piece of ML need explaining? It depends! As mentioned before, trust is often earned by systems we understand, which would lead to two assumptions:
- We need to explain ML that can’t be easily understood
- We need to explain ML that could seem scary or intrusive
When we talk about ML today, almost a decade after its first real strides in digital products, a lot of it is hidden and not fully public facing. For example, not a lot of people question which results Google or any other search engine shows them, they are easily relatable and expected! However, there’s a fair share of ML behind that computation. If you Google something, you’d have to search for a while to get a full explanation of the results.
Marketers have been trying to crack search engine algorithms for decades – but the average user doesn’t care
This changes when a ‘smart system’ leaves some room for interpretation. For example, recommendation systems on Amazon and Netflix generally tell us why they are showing us a certain thing. Netflix is well-known for using algorithms in every aspect of their user experience, including their recommendations.
So, let’s imagine that Netflix showed us a wall of movies without context. It would seem unexpected, random even. It’d be really hard to know what to expect.
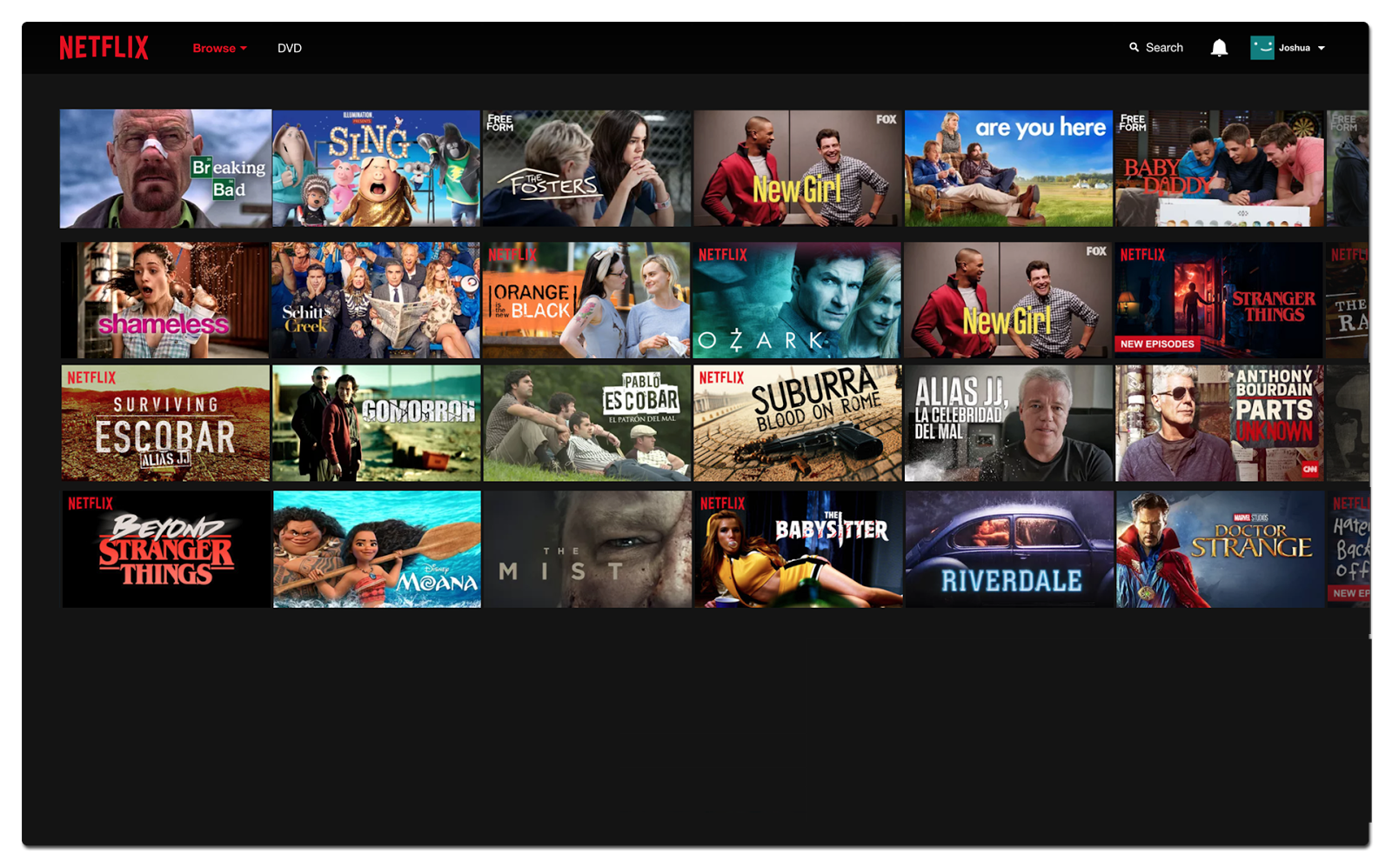
No explanation means expectations could be misaligned
Thankfully, Netflix doesn’t work like this. It shows you exactly what you’d like to watch, and why it shows it to you. You’d see categories like “Because you watched Narcos”, “Your top picks”, or even “Goofy Sci-Fi Cartoons and Animation” if Netflix knows you really well (thanks, Rick & Morty).
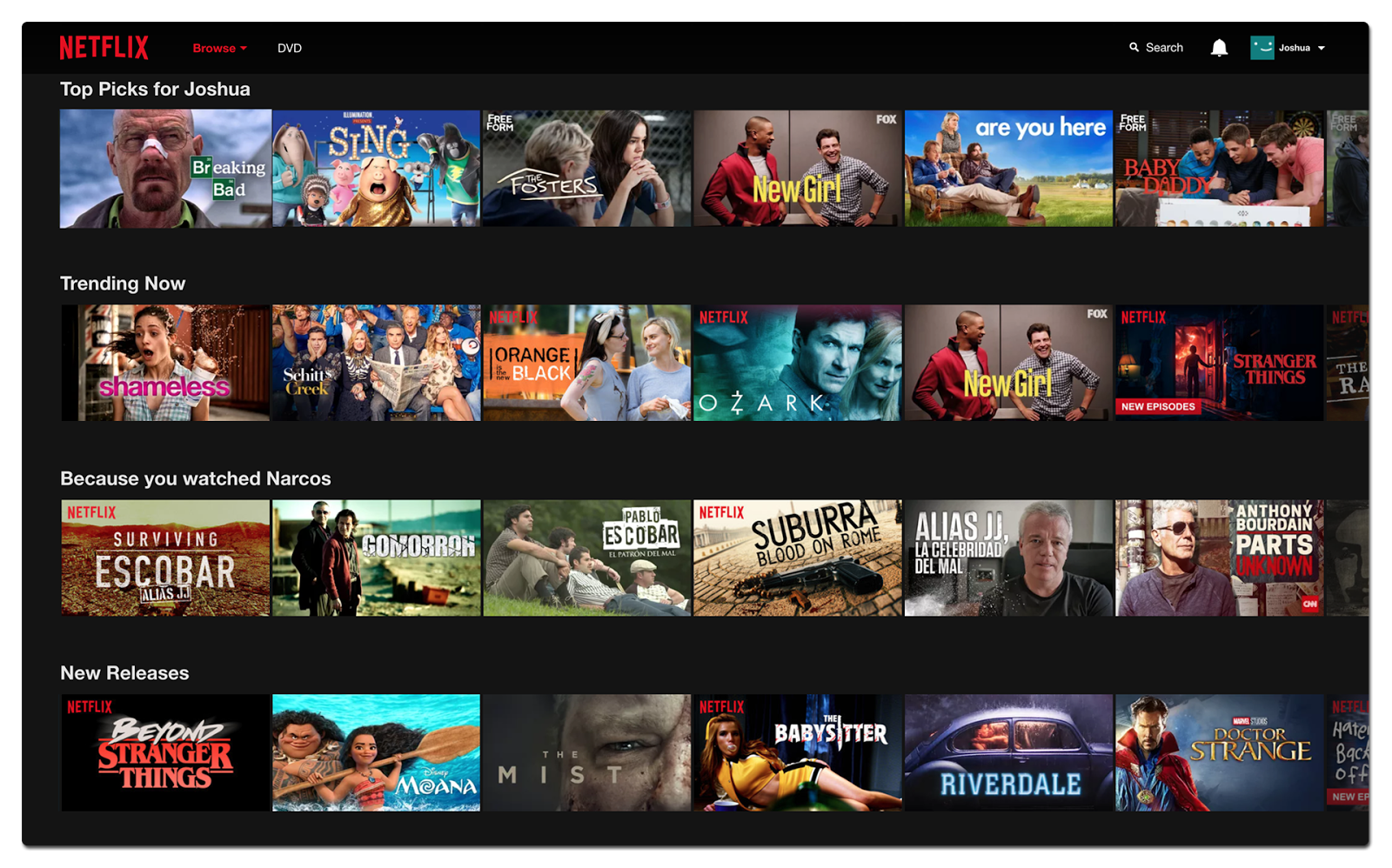
These categories are not only entertaining, they also add context
By giving this quick pointer, Netflix gives us all the context we need. Now it makes sense why Netflix is trying to get you to watch “Peaky Blinders” so bad. It’s because you binged all of Queen’s Gambit and people that like one usually like the other (or they love Anya Taylor-Joy ’s amazing acting in both). Explained!
Explaining behavioral tracking in advertising
Then, there’s the darker side of ML as well. It’s no secret that it is not only used to make your bingeful Netflix days even better. A lot of personal data gets collected in the process, and ends up being used in advertising.
The second reason ML needs to be explained is when it could be seen as intrusive or scary. Since the early 2010s, there’s been an unwritten law that ad networks should disclose when ML and personal data is used in tailoring ads. Through the AdChoice program, many advertising networks allow more control over behavioral targeting.
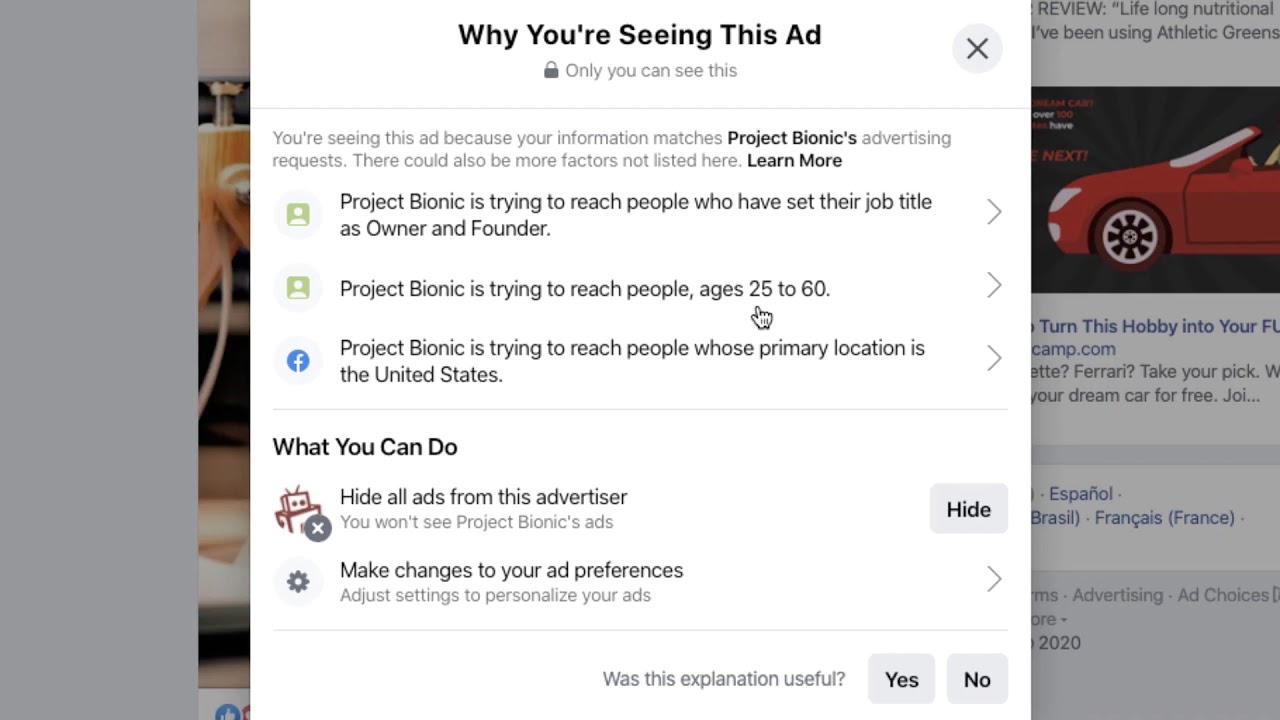
Disclosing data usage builds trust and makes the ad selection less mysterious
But even though the motivation behind explaining this use case of ML is different, the effect is the same. As much as showing AI-picked Netflix movies without any context can seem arbitrary and leaves room for interpretation, so does to not explain the decision to show a certain ad.
As we know this can lead to colorful interpretations of the ad selection. Why am I getting a car ad? Did Facebook listen to my conversation about cars? Did they get access to the huge repair bill I received a few weeks ago? No, probably it’s because the car brand is targeting young males that have recently visited car brand pages – simple!
Why ‘black box’ algorithms are not good enough
There’s a case to be made that there’s no incentive for brands and businesses to disclose and explain their ML decisions, and that’s understandable. By explaining, we also offer a small glimpse into the inner workings of an algorithm that we ourselves might not know everything about. A glimpse that may be unexpected, flawed, or even wrong. It’s high stakes for a business and a seemingly small reward. Both of these assumptions are flawed.
First, engineers working on ML should strive to learn the inner workings and decision-making of an algorithm they intend to push to production. One reason for that is to anticipate and create intuition for failure cases to either be able to improve the next version of an algorithm or create post-processing steps that help alleviate them. Not every failure case in ML is fixable and therefore it’s important not to blatantly show failure cases to the end user. For example, instead of showing a result with low probability (or confidence), a post-processing step could ask the user to check their data, re-take a picture, etc.

Engineers need to anticipate the limits of their models
The second reason why engineers and product teams should build a certain intuition for their models and test them thoroughly is to counteract algorithmic bias . For example, the training data could be skewed and entirely different from data in the wild, which would lead to incorrect behavior. Likewise, the distribution of data in production may just be entirely different – for example health data of people with two different sets of ethnicities – which can also create wrong outcomes.
People that work in the profession that we know today as ‘Machine Learning Engineer’ are usually informed about the existence and danger of algorithmic bias, but when it comes to detecting and preventing it, many will fall short. As production-ready ML gets more accessible to a wider audience, through tools like AutoML and CreateML , and starts becoming a toolkit of software engineers of all backgrounds it becomes even more important to make sure that bias is prevented as much as possible.
Explainable AI is good for trust – and your bottom line!
The claim that there’s no measurable value in explaining ML decisions has also been disputed. Research shows that ads become more effective if the targeting data used to train the algorithm is public and explained – provided that data used is deemed as acceptable. Even if the data used is widely deemed as unacceptable, such as cross-website tracking or inferred information, there’s only minimal loss in trust.
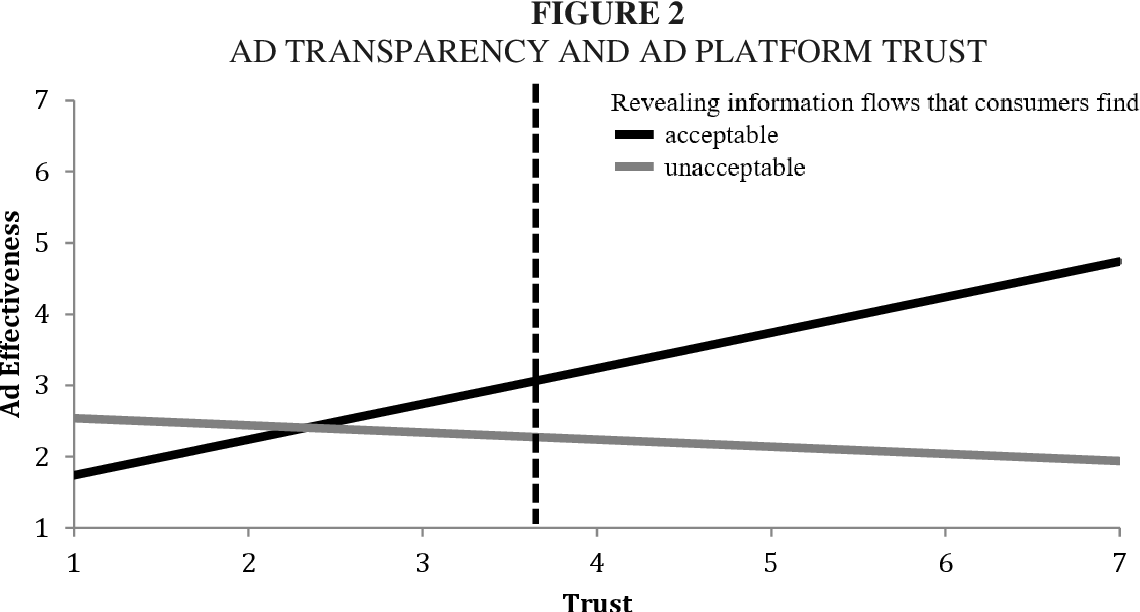
Showing targeting data usage is a win-win with only minimal downside
This seems to suggest that in many ethical use cases of ML, revealing information increases trust with consumers, which leads to more effectiveness in your targeting or business use cases. Even if information is deemed unacceptable by some users, it only confirms their existing suspicion and doesn’t increase it. With most ML in production today relying on in-house data, being transparent about its decisions can only benefit you.
Moving onto explainable, fair ML products
The question that’s left is – how can we make the seemingly ‘black box’ ML models transparent, visualize their decisions and create trust in what we do?
When we talk about ‘explaining’ a model, we most likely don’t need a full breakdown of the decisions and calculations that a model has made. In a production environment it’s usually enough to answer the question “what’s been the deciding factor in this decision?” The good news is, we have multiple ways to get there.
Disclosing data sources
The most straightforward way to shine some light into the black box that is ML is to disclose your data sources. For many tools, this is an easy way out because only minimal data is used in a decision, so there’s no need to give a complicated explanation and much easier to give the full picture instead.
Many ad networks that don’t use personal identifiable information will therefore just disclose all data that’s used for advertising.
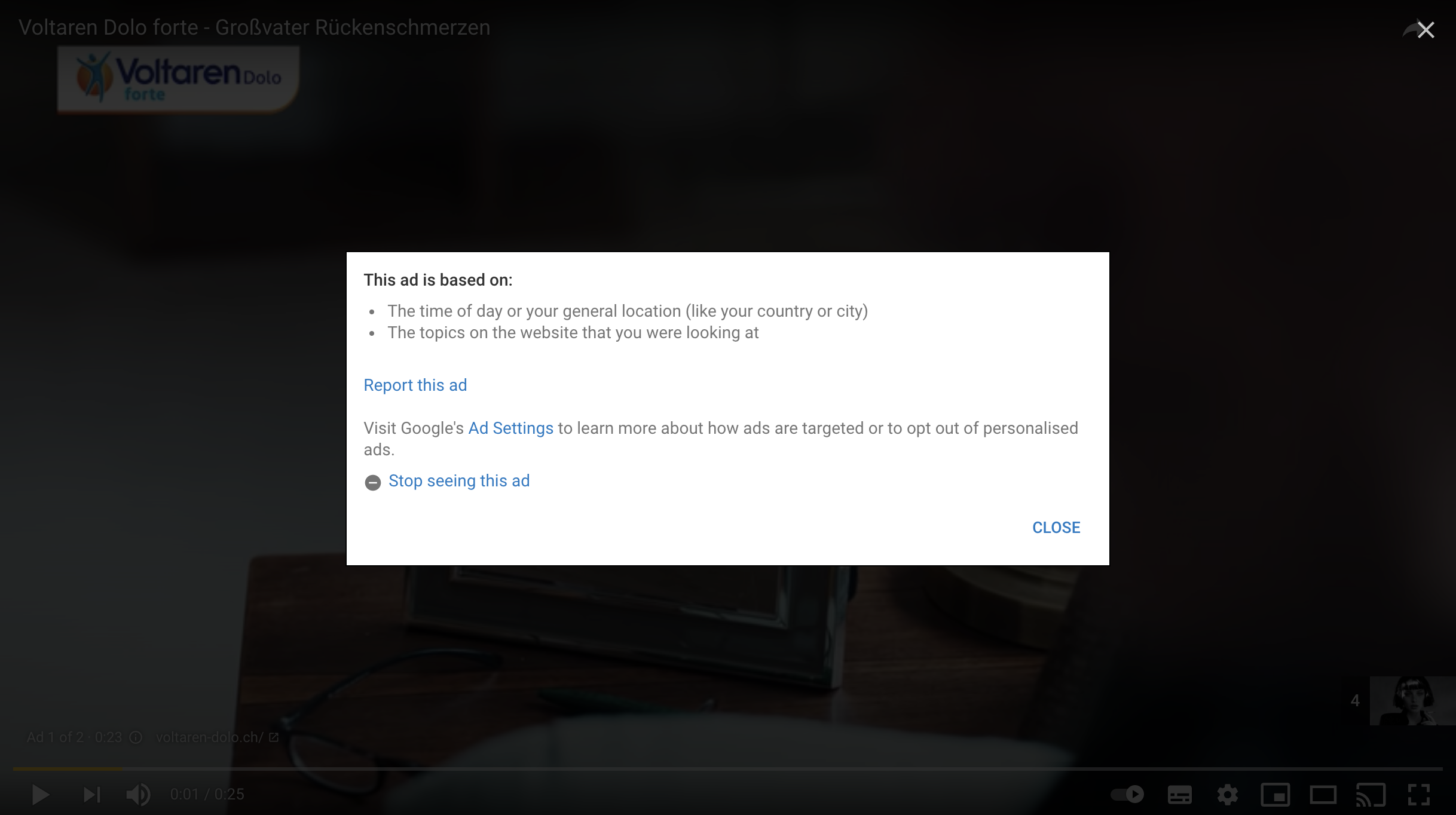
In an anonymous browser, the data Google can use for targeting ads is limited
In another example, social media platforms like Instagram will typically suggest you to follow certain accounts. Here it’s usually enough to show the name of the source account to justify the suggestions itself. We don’t need to visualize the exact decisions that have led the algorithm to the suggestions itself.
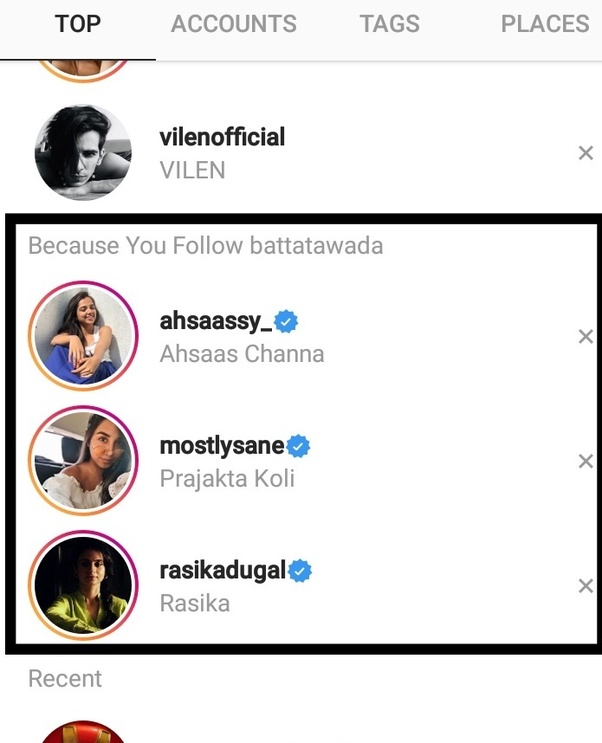
The source data is sometimes enough to explain a decision
The advantage of this method is clear: You reduce overhead and get to a simple, shippable solution very quickly. There’s also a disadvantage: We don’t actually end up explaining the decision a ML model has made. For many simple, non-intrusive uses of ML, this is just enough.
Use interpretable models
The easiest way to explain ML decisions is to use an algorithm that is “interpretable” by design. Interpretable models are often simpler models that allow us to zoom in on a specific sample, follow the decision path and deliver an accurate depiction of what went into a decision. This also means that we can zoom out, look at multiple samples at once and give a high-level overview of reasons that would influence certain ML decisions.
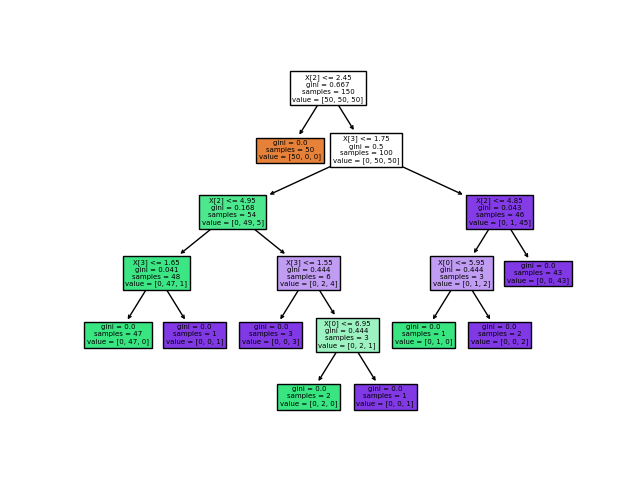
A decision tree is interpretable, we can follow the branches
Algorithms that are interpretable by design are for example Linear Regression , Decision Trees and K-Nearest Neighbors . While data scientists will generally try to extract the most accuracy out of their models through more powerful algorithms and ensembles that make it incredibly hard to trace back a decision, many of these models have the capacity needed for a large variety of production tasks that need to work fast, economically, accurately and reliably.
On the other hand, for many use cases having full interpretability of a model is overkill. What we really want in production is offering a glimpse, the main decision factor in an explanation, and rarely the full path it took to get there.
Explain black box models ‘as much as possible’
There are a few good reasons to keep the explanations of a model and the model itself apart. For one, if explanations can be made independently of the model, engineers are able to use whatever algorithm or ensemble that they want. Second, there’s more flexibility in the choice of explanation methods as well. We could use one that fits our use, or multiple that compete against each other.
Last but not least, explaining a model from the outside gives us a level playing field about what’s happening from a user perspective: given the input and the output, can we understand why a certain decision was taken?
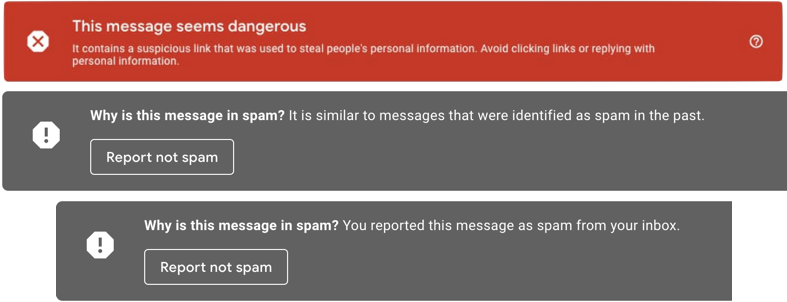
Gmail only offers us a small, but very relevant glimpse into their massive spam detection algorithm
Research in model-agnostic explanations has been the most active with the rise and popularity of non-interpretable ML algorithms.
Going into the leading algorithms that allow us to explain black box models, such as LIME and SHAP , is material for another time. In general, these techniques aim to provide either a global or local explanation.
Global Explanation
Providing a global explanation means giving a high-level overview about what the algorithm deems as important. For example, in a credit score evaluation that uses hundreds of personal attributes and features, what are the 5 key deciding factors that can influence the output?
Generating a global overview of a model is a good practice nonetheless. It helps engineers catch unwanted bias and gives a welcome place to start with debugging if one feature seems overpowering. Not only that, but it can also be a good place to start with providing explanations for a single sample and something that could be used as an explanation in production.
Local Explanation
A local explanation means computing and providing an explanation for a single sample. To get back to our credit score evaluation example, an agent could respond to inquiries with a local explanation, namely, the key factors that went into a specific decision.
The global explanations could be used for this, but it’s not always the most reliable: Factor A, G and L are the most important in our current model. Since factor G is positive for this decision, it must be the key deciding factor. This works and may even be a valid way to do it for certain products, but it’s certainly not the most accurate.
Other local explanation algorithms like LIME use more sophisticated ways to provide an insight into a model and specific decision, such as taking the input data of a certain discussion and slightly tweaking it one-by-one to find out which data perturbations create the biggest changes.
What explainable ML means for Doist
While we’re not new to ML at Doist, we’re certainly new to shipping it consistently. As we pushed more of our ML experiments to Twist , such as our first stab at a smart inbox and safety systems , it was apparent to us just how important explaining our model exactly is. Claiming that ML is “unpredictable”, a “black box”, or that “we don’t control things,” is simply not acceptable anymore.
In our experiments, we generally got good feedback from people that had an understanding and trust in ML, and worse feedback from folks that were not technical or were concerned about our data usage. Even though we only used our own in-house company data for training and didn’t even touch user data except for their own predictions, there were many questions and concerns we could’ve easily handled by providing more context and explanations.
In the future, we will increase our testing around explainability to the general public, and provide ML features that invoke more trust and are easier to understand.
Further reading
- Christoph Molnar: Interpretable Machine Learning, A Guide for Making Black Box Models Explainable.
- Conor O’Sullivan: Interpretable vs Explainable Machine Learning
- Google Cloud Hands-on Lab: Explaining ML Model Predictions
- Explaining explanations in AI, Mittelstadt et al.
- Why corporate AI project fail